Evaluator-Optimizer
Evaluator-Optimizer pattern allows an LLM to improve the quality of generation by optimizing a previous generation with feedback from an evaluator. This evaluation-optimization loop can be done multiple times.
Implementation
This pattern consists of five subtasks. Each subtask is implemented using Task Execution pattern. Only the task to generate the initial result is required. All other four subtasks are optional.
- A task to initialize the input for generation.
- A task to generate the initial result.
- A task to evaluate the result and provide feedback.
- A task to optimize a previous result based on the feedback.
- A task to finalize the response.
The flow chart below shows the basic steps.
Use Different Models
It's recommended to use different models for generation and evaluation to get better results. For example, we can use GPT-4.1 for generation and DeepSeek V3 for evaluation, or vice versa.
Max Number of Evaluations
It's recommended to set a limit to the maximum number of evaluations. After finishing the maximum number of evaluations, result of the last generation will be returned, even though it doesn't pass the evaluation. This will reduce the response time and cut down the costs.
Evaluation Results
For the evaluation result, it can be a boolean type with values yes or no, or a numeric type with the score from 0 to 100. Numeric scores can be more flexible, as we can set different thresholds to mark the result as passed or not passed. When combined with Parallelization Workflow pattern, we can run multiple parallel evaluations and use the average score as the final score.
Example
Let's see an example. The example is to generate code with multiple rounds of reviews.
Generate Initial Result
To generate the initial result, the prompt template only contains the task input. The template variable input represents the task input. Java code will be generated.
Goal: Generate Java code to complete the task based on the input. Output *only* the code. No explanations.
**Task**
{input}
Output of this task is the generated code.
Evaluate
After generating the initial result, we can evaluate the generated code. The template variable code is the code to evaluate. The template lists several rules to evaluate the code.
Goal: Evaluate this code implementation for correctness, time complexity, and best practices.
Requirements:
- Ensure the code have proper javadoc documentation.
- Ensure the code follows good naming conventions.
- The code is passed if all criteria are met with no improvements needed.
**Code**
{code}
Below is the type of evaluation results. Here a boolean result passed is used. feedback is the feedback provided by the evaluator when not passed.
package com.javaaidev.agenticpatterns.evaluatoroptimizer;
import com.fasterxml.jackson.annotation.JsonPropertyDescription;
import org.jspecify.annotations.Nullable;
/**
* Boolean evaluation result
*
* @param passed Passed or not passed
* @param feedback Feedback if not passed
*/
public record BooleanEvaluationResult(
@JsonPropertyDescription("If evaluation passed") boolean passed,
@JsonPropertyDescription("Feedback of evaluation") @Nullable String feedback) implements
EvaluationResult {
@Override
@Nullable
public String getFeedback() {
return feedback();
}
}
Optimize
If the evaluation result is not passed, then the code can be optimized based on the evaluation feedback. The template variable code represents the code to optimize, while feedback representing the feedback from the evaluator.
Goal: Improve existing code based on feedback. Output *only* the code. No explanations.
**Requirements**
- Address all concerns in the feedback.
**Code**
{code}
**Feedback**
{feedback}
The output is the optimized code. Optimized code will be evaluated again util it passes the evaluation, or after the maximum number of evaluations.
Example Result
The picture below shows the trace of an execution of this agent. Trace name agent.execute means an execution of an agent. The outer trace represents the execution of the code generation agent. There are four traces nested in the outer traces. In the order of executions, these four traces are:
- Generation of the initial result.
- First evaluation, not passed.
- First optimization.
- Second evaluation, passed.

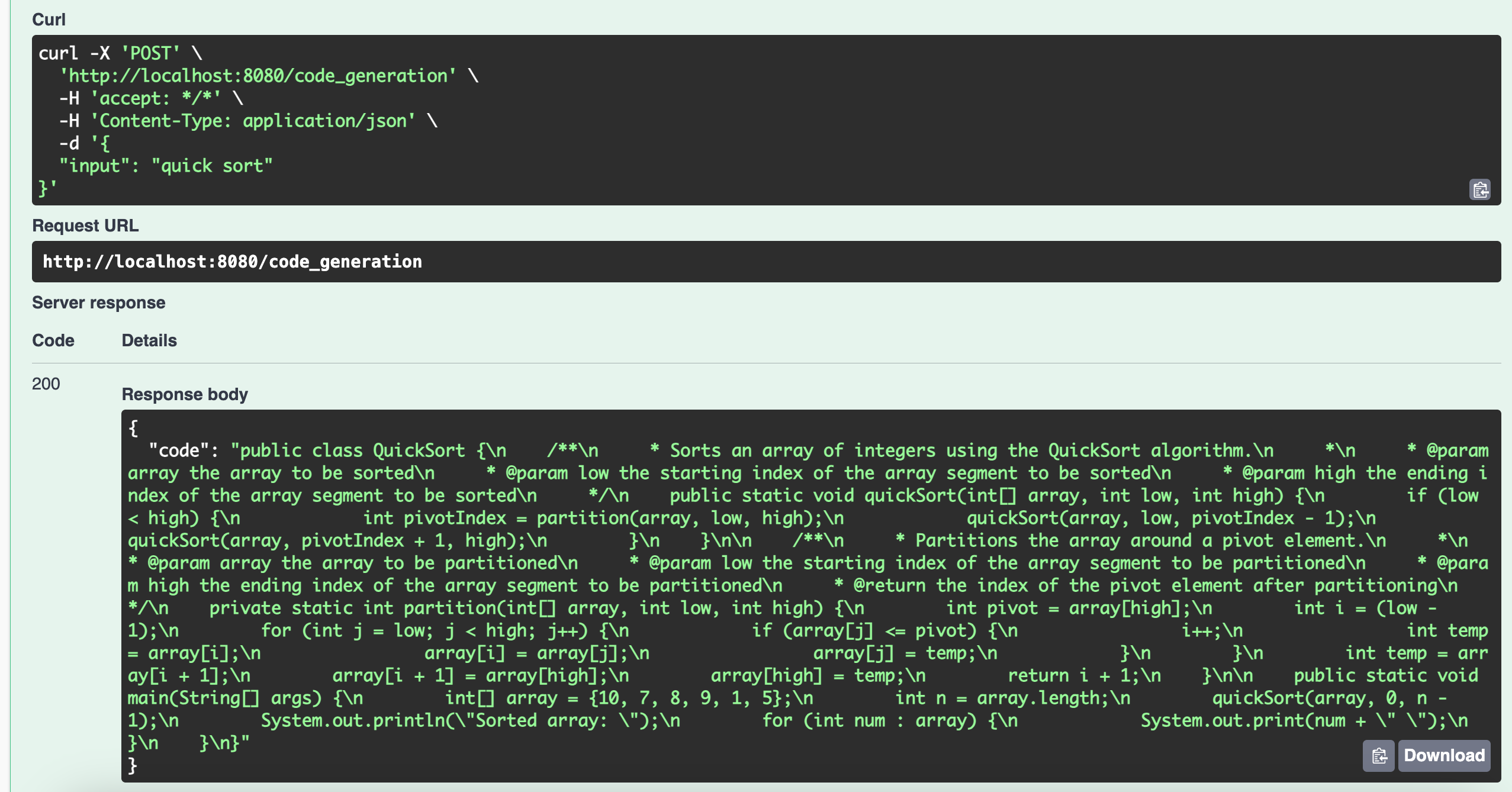
The result that passes the evaluation will be the final result. The screenshot below shows the result of using Swagger UI to test the agent. The input is "quick sort", the output is generated Java code.
Reference Implementation
See this page for reference implementation and examples.