Parallelization Workflow
Parallelization Workflow pattern runs subtasks in parallel to improve the performance.
Depends on whether these tasks return the same structure of data, there are two types of parallelization workflows.
Subtasks return different types of data
This kind of parallelization workflows decompose a large task into multiple smaller subtasks. These subtasks are executed in parallel. The final result of this agent will be assembled from execution results of these subtasks.
A typical example of using this type of workflow is writing reports. The agent creates different subtasks to gather information for different areas, then assembles results from these subtasks to create the final report.
Subtasks return same type of data
This kind of parallelization workflows use multiple subtasks for voting or confirmation. These subtask give different results for the same input. The agent uses these results to determine its final result.
For the code generation example described in Evaluator-Optimizer pattern, the agent for evaluation can run three parallel subtasks to evaluate the code using three different models. Each subtask returns the result of passed or not passed. The agent can use the result with majority as its final result.
Implementation
This pattern consists of a main task and a flexible number of subtasks. The main task and each subtask are implemented using Task Execution pattern.
Result Types of Subtasks
Subtasks may return results of different types or the same type.
Different Types
If subtasks return different types of results, they typically require different types of inputs. In this case, before executing a subtask, the original task input needs to be transformed into the type required by a subtask.
Same Type
If all subtasks return the same type of results, then the original input can be passed to subtasks directly.
Assembling Strategy
When all subtasks finish execution, there are two strategies to assemble the results.
- The first assembling strategy doesn't use an LLM. It simply takes the results of all subtasks and assemble them using code logic.
- The second assembling strategy uses an LLM. Results from subtasks are passed to an LLM for further generation.
Rate Limits
When implementing this pattern, we should pay attention to rate limits of calling AI services. With subtasks running in parallel, it's very easy to reach rate limits. To avoid rate limiting, we can restrict the number of parallel running tasks. We can also restrict the total number of executed tasks in a certain time range.
Example
The example is an agent to write articles about algorithms. Each article has code examples written in different programming languages. A parallelization workflow agent runs parallel subtasks to generate code examples, then generates an article using these code examples.
Let's start from the input and output of this agent. The input contains two fields:
algorithmrepresents name of the algorithm.languagesrepresents the list of programming languages.
package com.javaaidev.agenticpatterns.examples.parallelizationworkflow;
import java.util.List;
public record AlgorithmArticleGenerationRequest(
String algorithm,
List<String> languages) {
}
The output only contains one field.
articlerepresents the generated article.
package com.javaaidev.agenticpatterns.examples.parallelizationworkflow;
public record AlgorithmArticleGenerationResponse(
String article) {
}
Parallel subtasks use the prompt template below to generate code samples.
Write {language} code to meet the requirement.
{description}
After all subtasks finish execution, their results are collected and used to generate the article. An LLM is used to assemble the results. In the prompt template below, the value of sample_code variable is generated from results of all subtasks.
Goal: Write an article about {algorithm}.
Requirements:
- Start with a brief introduction.
- Include only sample code listed below.
- Output the article in markdown.
{sample_code}
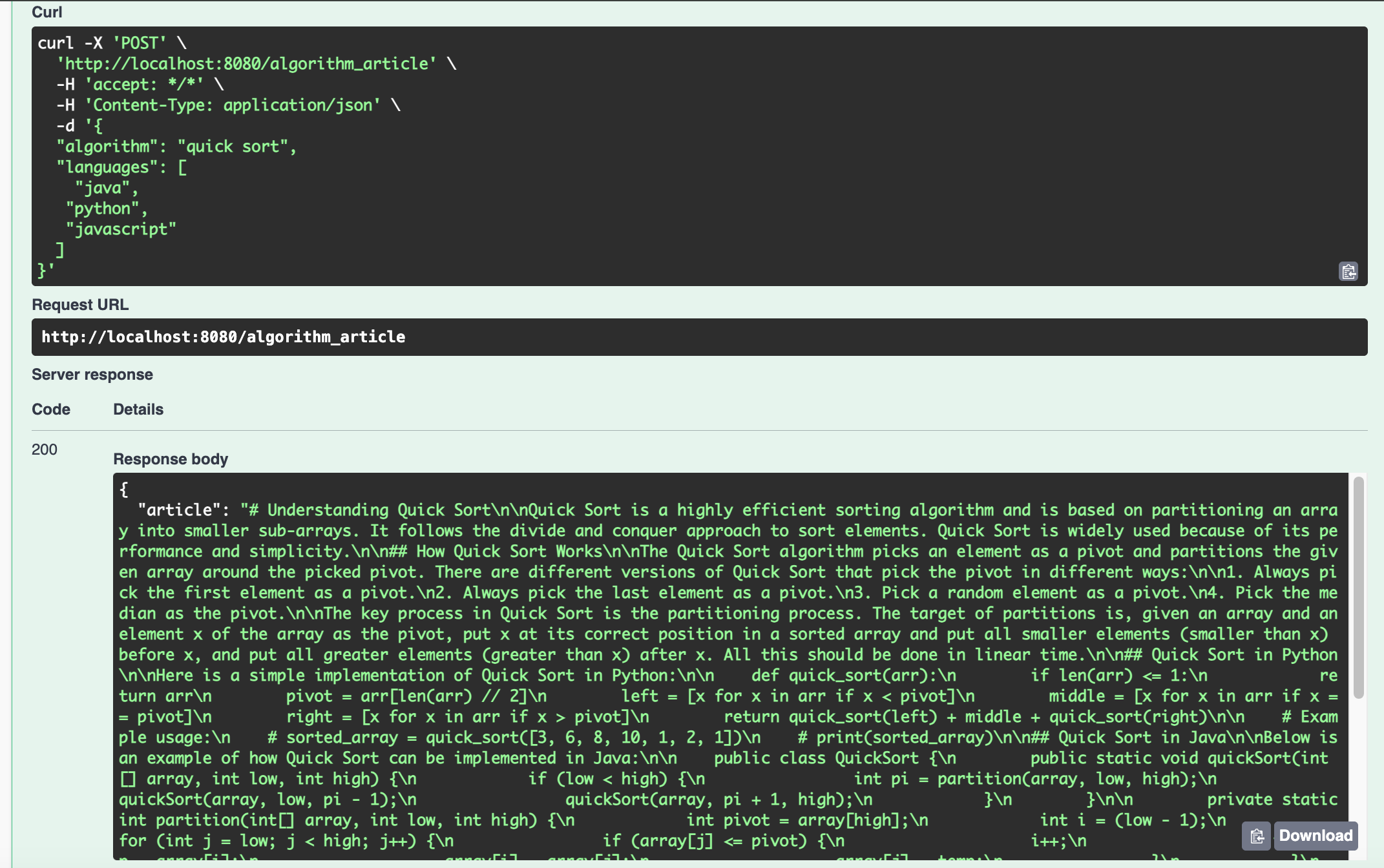
Below is a sample input of this agent. The task is to generate an article about quick sort with code samples of Java, Python, and JavaScript.
{
"algorithm": "quick sort",
"languages": [
"java",
"python",
"javascript"
]
}
The picture below shows the trace of an execution of this agent. Trace name agent.execute means an execution of an agent. The outer trace represents the execution of the article generation agent. Those three nested agent.execute traces represent executions of subtasks to generate code samples of three languages. These three subtasks run in parallel.

The screenshot below shows the result of using Swagger UI to test the agent. The output is a generated article.
Reference Implementation
See this page for reference implementation and examples.